Protein Engineering Canada Portal
The Protein Engineering Community brings together computational tools, structural biology workflows, and analytical pipelines that support protein design, biomolecular characterization, and systems research. Some of these resources are featured below. If you have developed a relevant tool or workflow and would like it linked here, we would be happy to hear from you.
Click here to access the 6th PEC Conference website

Useful tools developed by the global protein engineering community
The links below are provided as a curated list of useful community resources for protein engineering and related fields. Inclusion on this page does not imply endorsement, ownership, or responsibility for external content. If you are the developer of a listed tool and would prefer that we remove or modify the link, please contact us and we will be happy to do so.
SPASE
Soluble Protein Analog Selection Engine
SPASE is a protein engineering pipeline built around ProteinMPNN as its core generative engine, combined with complementary biophysical filters. From a monomeric structure, it generates approximately 10,000 sequences, then filters them using Protein-Sol, ESMFold, and Aggrescan3D. It prioritizes stable, soluble, and expressible variants, with optional residue constraints to preserve function.
Suns
The Structural Search Engine
Suns is a structural search engine for protein databases that integrates with PyMOL. It enables users to build all-atom motif queries, find and align similar structures, and validate designed or modeled proteins against experimentally determined structures.
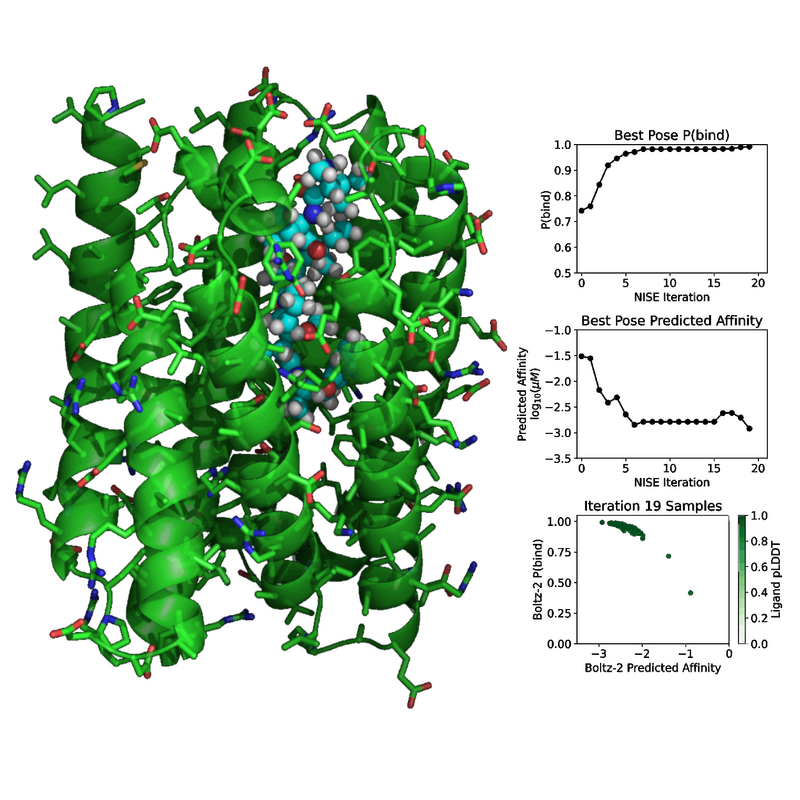
Neural Iterative Selection Expansion
NISE
NISE is a protein design pipeline that generates sequences from structural backbones by iteratively combining sequence design and structure prediction, while enforcing ligand and geometric constraints to produce candidate proteins consistent with a target binding or structural objective.

AggreProt
AggreProt is a web server that uses deep convolutional neural networks to predict protein aggregation and engineer solubility. It provides per-residue and overall aggregation scores, incorporating solvent accessibility and transmembrane propensity. It is sequence-based, trained on amyloid hexapeptides, and mainly detects short amyloid-prone regions.
LoopGrafter
LoopGrafter provides guidance for transplanting loops between two structurally related proteins, defined as scaffold/source and insert/target, while assessing their dynamic properties. For best use, grafting is recommended on proteins that differ by no more than 8 Å RMSD and less than 20% of sequence length.

PredictONCO
PredictONCO is a web tool for automated and fast analysis of the effects of mutations on stability and function in known cancer targets. It applies molecular modeling, bioinformatics, and machine learning approaches, and supports treatment-oriented analysis by evaluating mutation effects on binding to FDA- and EMA-approved drugs.

SoluProtMutDB
SoluProtMutDB is a curated database of protein solubility data for single- and multi-point mutants, compiled from published studies. It documents how mutations affect solubility and provides standardized, machine-learning-ready data to support protein engineering and the design of more soluble protein variants.

FireProtASR
FireProtASR is a web server for automated ancestral sequence reconstruction from a single protein sequence. It builds homolog datasets, performs alignment, phylogenetic tree construction, and ancestral sequence inference with gaps. It supports both fully automated workflows and user-provided data at different pipeline stages.

CAVER Web 1.0
CAVER Web is an interactive server for analyzing protein tunnels, channels, and ligand transport. It integrates CAVER for tunnel detection and CaverDock for transport simulation, with guided setup for users. It supports multiple ligand inputs and provides fast, accurate results with moderate computation time.

SoluProt 1.0
SoluProt is a web application that predicts protein solubility from amino acid sequence using a random forest model with 36 sequence-derived features. It generates a solubility score to prioritize experimental protein production and is trained on physicochemical, structural, and homology-based descriptors.

EnzymeMiner 1.0
EnzymeMiner is a web application that automatically mines genomic databases for enzyme sequences with conserved catalytic residues. It integrates sequence and structural bioinformatics, including structure prediction, cavity and tunnel analysis, and enzyme–substrate modeling, to identify and assess functionally diverse candidates for a defined enzymatic reaction.

CalFitter 2.0
CalFitter is a tool for analyzing and fitting protein melting curves from differential scanning calorimetry data. It supports global fitting across scan rates and reheating using multiple unfolding models, and outputs intermediate populations, fitted parameters with confidence intervals, and results exportable to Excel.